Image Classification: An Overview

I create cross platform mobile apps with AI functionalities. Currently a PhD Scholar at Indira Gandhi Delhi Technical University for Women, Delhi. M.Tech in Artificial Intelligence (AI).
Image classification is a computer vision task that involves assigning a label or category to an image based on its visual content. It's like teaching a computer to recognize different objects and scenes. For instance, an image classification model could differentiate between a cat and a dog, a mountain and a beach, or a car and a truck.
Image Classification aims to understand and categorize an image as a whole under a specific label. Unlike object detection, which involves classification and location of multiple objects within an image, image classification typically pertains to single-object images. When the classification becomes highly detailed or reaches instance-level, it is often referred to as image retrieval, which also involves finding similar images in a large database.
How Does it Work?
Image classification models typically use deep learning techniques, particularly convolutional neural networks (CNNs). CNNs are designed to process and analyze visual data. They extract features from the image, such as edges, textures, and shapes, and then use these features to make predictions.

Steps for Image Classification
Data Collection: Gather a large dataset of images, each labeled with the correct category.
Data Preprocessing: Prepare the images for training by resizing, normalizing, and augmenting them (e.g., rotating, flipping).
Model Architecture: Choose a suitable CNN architecture, such as AlexNet, VGG, ResNet, or a more recent model.
Training: Feed the preprocessed images into the model and adjust its parameters using backpropagation to minimize the error between predicted and actual labels.
Evaluation: Assess the model's performance on a validation set to ensure it generalizes well to unseen data.
Inference: Use the trained model to classify new, unlabeled images.
Applications
Medical Imaging: Diagnosing diseases from X-rays, MRIs, and CT scans.
Self-driving Cars: Recognizing objects like pedestrians, traffic signs, and other vehicles.
Retail: Organizing and searching product images.
Security: Facial recognition, object detection in surveillance footage.
Remote Sensing: Analyzing satellite images for land use, deforestation, and climate change.
Current Challenges
Small Datasets: Training effective models can be challenging with limited data.
Data Bias: Biased datasets can lead to biased models, perpetuating societal inequalities.
Interpretability: Understanding why a model makes a particular prediction is often difficult.
Transfer Learning: Leveraging pre-trained models to improve performance on new tasks with limited data.
Few-Shot Learning: Classifying images with very few examples.
Machine Learning for Image Classification
Machine learning for image classification involves using algorithms to classify images based on features extracted from them. In this approach, features such as edges, textures, and colors are manually designed and selected. Algorithms like Support Vector Machines (SVM) and k-Nearest Neighbors (k-NN) then use these features to make predictions. This method is less computationally intensive and can work well with smaller datasets. However, it often requires significant effort in feature engineering and may struggle with complex or large-scale image data.
Why ML for Image Classification
Simplicity and Efficiency: Machine learning approaches can be simpler and more efficient for smaller datasets or less complex problems. They require less computational power compared to deep learning, making them suitable for environments with limited resources.
Interpretability: Many traditional machine learning models, such as decision trees or SVMs, offer better interpretability. This means it’s easier to understand how the model makes its predictions, which is valuable for applications requiring transparency.
Faster Training: Training machine learning models can be faster, especially with smaller datasets. They often don’t require extensive hardware resources or long training times.
Feature Engineering: When feature extraction techniques are well-understood and effective, traditional ML methods can perform well without the need for complex neural networks.
Deep Learning for Image Classification
Deep learning for image classification uses advanced neural networks, particularly Convolutional Neural Networks (CNNs), to automatically learn features from raw image data. Instead of manually designing features, deep learning models learn to recognize patterns and structures through multiple layers of the network. This approach excels in handling large and complex datasets, achieving high accuracy, and capturing intricate patterns in images. Although it demands substantial computational resources and large volumes of data, deep learning has become the leading method for image classification tasks due to its ability to handle complex image data effectively.
Why DL for Image Classification?
Automatic Feature Learning: Deep learning models, particularly Convolutional Neural Networks (CNNs), automatically learn relevant features from raw images. This eliminates the need for manual feature engineering and can capture complex patterns and hierarchical structures in data.
High Accuracy: Deep learning models excel in performance and accuracy, especially with large and diverse datasets. They can handle complex image classification tasks that traditional methods might struggle with.
Scalability: Deep learning scales well with large datasets and high-dimensional data. As the amount of data increases, deep learning models often continue to improve, making them suitable for big data applications.
Versatility: Deep learning can be applied to a wide range of image classification problems and can handle various types of images and tasks, including object detection and segmentation, beyond simple classification.
State-of-the-Art Performance: For many modern image classification challenges, deep learning methods provide state-of-the-art performance and have set new benchmarks in accuracy and efficiency.
Convolution Neural Network
Convolutional Neural Networks (CNNs) are a class of deep learning algorithms specifically designed for processing structured grid data, such as images.
Architecture
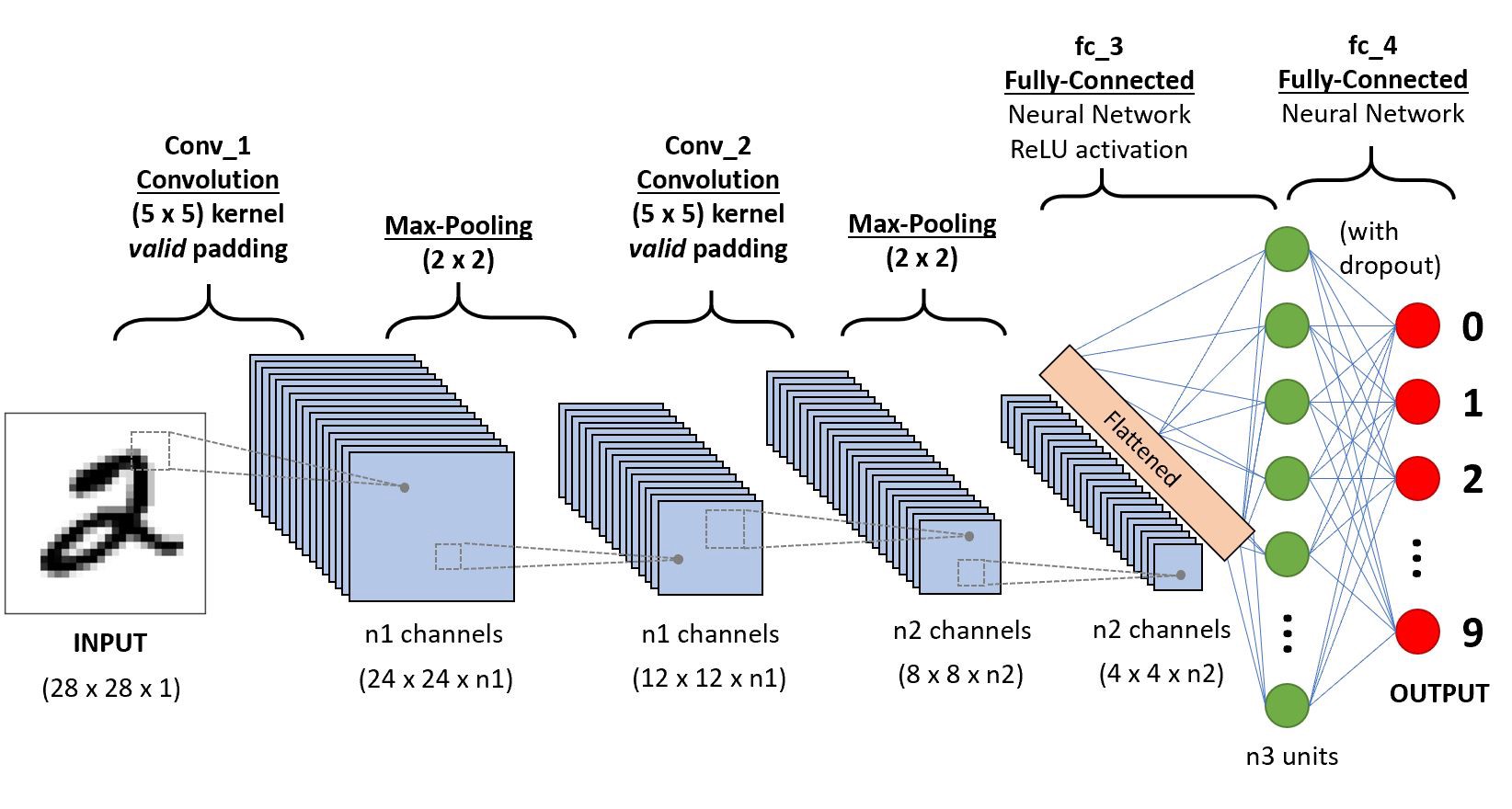
Following are the layers used in CNN
Input Layer
The input layer receives the raw image data. Images are usually represented as a 3D tensor with dimensions corresponding to height, width, and number of color channels (e.g., RGB channels).
Example: An image of size 224x224 pixels with 3 color channels (RGB) would be represented as a tensor of shape (224, 224, 3).
Convolutional Layers
It extracts features from the input image by applying convolutional filters (kernels). These filters slide over the image to detect local patterns such as edges, textures, and shapes.
Operation: Each filter performs a convolution operation, producing a feature map (activation map) that highlights the presence of specific features in different parts of the image
Parameters: Filter size (e.g., 3x3, 5x5), stride (the step size of the filter movement), and padding (adding borders to the image to control the spatial dimensions).
Activation Functions:
Activation functions introduce non-linearity into the network, enabling it to learn complex patterns and representations.
The most commonly used activation function is Rectified Linear Unit (ReLU), which replaces negative values with zero and keeps positive values unchanged, enhancing computational efficiency and alleviating the vanishing gradient problem.
Variants like Leaky ReLU and Parametric ReLU address issues with inactive neurons by allowing a small gradient for negative inputs. Exponential Linear Unit (ELU) offers smooth activation with reduced vanishing gradient problems.
The choice of activation function can significantly affect a CNN's performance, often requiring experimentation to optimize for the task at hand.
Pooling Layers
Reduce the spatial dimensions (width and height) of the feature maps while retaining the most important information. This helps in reducing computational complexity and making the network more invariant to small translations of objects
Example: Typically reduces the feature map size by a factor (e.g., from 224x224 to 112x112).
Fully Connected Layers
After the convolutional and pooling layers, the high-level features are flattened into a 1D vector and passed through fully connected layers to perform classification or regression tasks.
Each neuron in a fully connected layer is connected to all neurons in the previous layer, allowing the network to combine features learned in earlier layers for decision making.
Dropout Layer
Optional Layer
Regularize the network by randomly dropping neurons during training to prevent overfitting.
During training, a fraction of neurons are randomly set to zero, forcing the network to learn more robust features.
Output Layer
Produce the final output of the network, such as class probabilities in classification tasks.
Activation Function: For classification tasks, a softmax activation function is used in the output layer to convert logs into probability distributions over the classes.
Benefits
Feature Hierarchy: CNNs automatically learn hierarchical features, starting from low-level features (like edges) to high-level features (like shapes and objects), improving the model's ability to recognize complex patterns.
Parameter Sharing: By using the same filter across different parts of the image, CNNs reduce the number of parameters compared to fully connected networks, making them more efficient and less prone to overfitting.
Spatial Invariance: Pooling layers help CNNs become invariant to small translations of objects within the image, allowing the model to recognize objects regardless of their position.
Performance Metrics
Performance metrics for image classification are used to evaluate how well a model performs in categorizing images into predefined classes
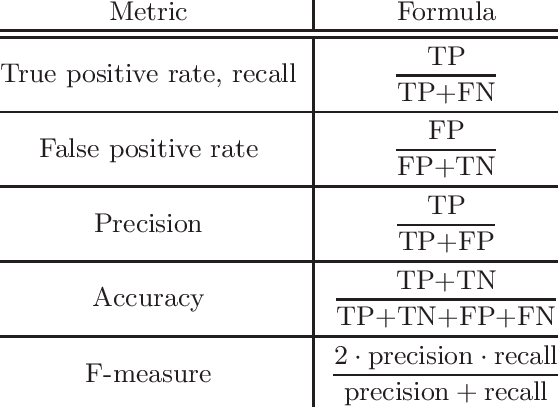
Accuracy: The ratio of correctly predicted instances to the total number of instances. It provides a general measure of performance, especially useful when class distribution is balanced.
Precision: The ratio of correctly predicted positive observations to the total predicted positives. It is useful where the cost of false positives is high. For example, in medical imaging, it is crucial to minimize false positives.
Recall (Sensitivity): The ratio of correctly predicted positive observations to all actual positives. It is useful when the cost of false negatives is high. For example, in detecting diseases, high recall ensures that most cases are identified.
F1 Score: The harmonic mean of precision and recall, providing a single metric that balances both. It is useful when you need to balance precision and recall, particularly in imbalanced datasets where neither metric alone may be sufficient.
Confusion Matrix: A table that describes the performance of a classification model by showing true positives, true negatives, false positives, and false negatives.
Area Under the Receiver Operating Characteristic Curve (ROC-AUC): Measures the model's ability to distinguish between classes by plotting the true positive rate against the false positive rate across different thresholds.
Area Under the Precision-Recall Curve (PR-AUC): Measures the trade-off between precision and recall for different thresholds. It is particularly useful for imbalanced datasets where positive class is rare.
Types of Image Classification
Binary Classification
Binary classification involves categorizing images into one of two distinct categories. This straightforward task determines whether an image belongs to one class or the other. For instance, in a binary classification problem, a model might be trained to identify whether a given image contains a cat or not, effectively distinguishing between "cat" and "no cat." This type of classification is fundamental and is often used as a starting point for more complex tasks.
Multi-Class Classification
Multi-class classification involves sorting images into one of several possible categories, where each image is assigned to only one class. For example, a model might be trained to recognize handwritten digits, classifying each image into one of ten classes (0 through 9). Unlike binary classification, multi-class classification deals with multiple categories, requiring the model to differentiate between a larger number of classes.
Multi-label Classification
Multi-label classification is used when an image can belong to multiple categories simultaneously. Unlike single-label classifications, where an image is assigned to one category, multi-label classification allows for multiple labels to be applied to a single image. For instance, an image of a beach at sunset might be labeled with both "beach" and "sunset," reflecting the presence of multiple relevant features or concepts.
Hierarchical Classification
Hierarchical classification involves categorizing images through a hierarchy of categories, where classification occurs at multiple levels. At the first level, the model might distinguish between broad categories such as animals and vehicles, and at subsequent levels, it might classify specific types within those categories, like distinguishing between different species of animals or car models. This approach provides a structured way to handle complex classification tasks by breaking them down into simpler, hierarchical steps.
After Words
I hope that this tutorial was helpful to you.




